多モードマッチング問題、文字列マッチングに関連するデータ構造
コース内容#
多モードマッチング問題
複数のパターン文字列のマッチング問題、一般的な考え方は以下の通りです:
- Step1:複数のパターン文字列を使って、辞書木を構築する
- Step2:テキスト文字列の各位置と整列してマッチングを行い、暴力的マッチングのプロセスをシミュレートする
Trie#
別名辞書木、単語検索木、名の通りの機能
図を見て理解する#
-

- 木の意味を考える:ノードは集合を表し、辺は関係を表す
- 根ノードは全体の辞書と理解でき、最初の文字が 'a' の単語は最初の部分木に、最初の文字が 'c' の単語は 2 番目の部分木に配置される、以下同様に
- 赤いノードは、根ノードから現在のノードまでのパス上で通過した文字が独立した単語を形成することを示す
- 特定の文字を表す辺が存在する場合 [ノードを指す]、以前の文字を接頭辞とする単語の集合が存在することを示す
- [PS] 接頭辞木とも呼ばれる:各文字列は接頭辞の順序に従ってこの木構造に挿入される
よく使われるシーン#
- ① 単語検索
- 特定の文字を表す辺がノードを指しているかどうかを判断し、特定の文字が存在するかを確認することで単語を検索する
- ② 文字列のソート
- 辞書木を深さ優先で探索し、単語マークに出会ったら文字列を出力することで、文字列の順序付き出力を完了する
- 時間計算量:$O (n)$、文字列のサイズ比較はなし
- ③ 多モードマッチング
- 1 つの辞書木は複数のパターン文字列を表すことができ、テキスト文字列の各位置を順に辞書木の文字列とマッチングすることで多モードマッチングを完了する
- しかし、この方法は本質的には多モードマッチングにおける暴力的マッチング方式である
暴力的マッチングの考察#
-

- まず暴力的マッチングプロセスを考える
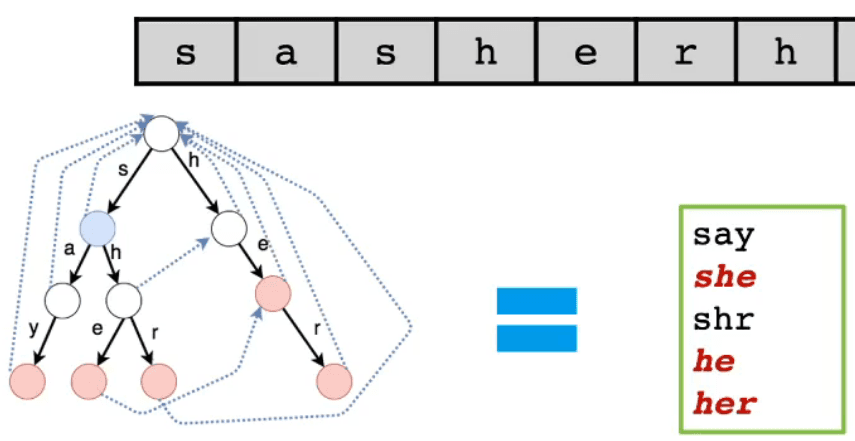
- 辞書木を使用してテキスト文字列の "she" を成功裏にマッチングした後、辞書木はさらに 1 つ下に進み、テキスト文字列の次の文字 'r' をマッチングしようとする
- しかし、この時点で辞書木の下にはノードが存在せず、マッチングに失敗する
- テキスト文字列のポインタは 'h' に戻り、辞書木のポインタは根ノードに戻ってマッチングを再試行し、その後 "her" を成功裏にマッチングする
- 上記のプロセスには明らかな重複マッチングプロセスがある
- "she" を成功裏にマッチングした後、実際には等価に "he" を成功裏にマッチングしたことになる
- したがって、テキスト文字列のポインタが 1 つ進むと、実際には "her" を成功裏にマッチングできるはずである
- これには等価マッチング関係が含まれている [下の図の赤線を参照]
-

- 辞書木の下にマッチングするノードがない場合、等価マッチング関係の側でマッチングできるかどうかを確認することができる
- ❗ 等価マッチング関係を通じてマッチングプロセスを加速できるか?AC オートマトンが答えを示した 👇
-
AC オートマトン#
状態機械の考え方、多モードマッチング問題の効率的解決
AC = Trie + fail [等価関係]
等価マッチング関係の構築#
マッチングプロセスを加速する
-

- ① 各子ノードに対して、そのデフォルトの等価マッチング関係は根ノードである
- ② 子ノードの等価マッチング関係を構築する際、親ノードの等価関係を利用する
- もし見つからなければ、さらに祖父ノードの等価関係を探し、根ノードに達するまで続ける
- ❗ 上に向かって等価関係を探す考え方は、KMP の $next$ 配列の構築の考え方と全く同じである、ジャンプすることができる:《高度なデータ構造》——4 文字列マッチングアルゴリズム(上)
- 例えば:'s'->'h' の 'h' の等価マッチング関係を探す際、親ノード's' の等価マッチング関係 [すなわち根ノード] に基づいて等価マッチング関係を探し、根ノードの下にちょうど 'h' があるため、等価マッチング関係 $A$ が構築された
- 注意
- 等価マッチング関係を構築する際、そのノードの上層の等価マッチング関係がすでに構築されていることを確認する必要があるため、レベル順探索の方法を採用し、キューを使用する
- 等価マッチング関係は通常 $fail$ ポインタと呼ばれる
マッチングプロセス#
現在の状態で文字をマッチングし、マッチングに失敗した場合は等価マッチング関係に移動してマッチングする
- ① 状態遷移
- 例えば:"sas"、2 番目の's' をマッチングする際にマッチングに失敗するため、等価マッチング関係 —— 根ノードに戻り、再度's' をマッチングしようとする;成功裏にマッチングするまで、または等価マッチング関係が空になるまで [すなわち根ノードも見つからない]
- [PS] プログラム実装において、根ノードの等価マッチング関係を NULL に設定すると便利である
- ② 単語を取得する
- 単語マークにマッチングした後、さらに上に等価マッチング関係の単語マークを確認する必要がある
- 例えば:テキスト文字列の単語 "she" を成功裏にマッチングした場合、等価関係の単語 "he" も成功裏にマッチングしたことを意味する
- 考察:この時の AC オートマトンは本質的にNFA[非決定性有限オートマトン] である
- [仮定:"she" は辞書木のノード $P$ に対応し、"he" は辞書木のノード $Q$ に対応する]
- 性質 1:現在の状態 $p$ で、入力文字 $c$ の後、次の状態を 1 ステップの操作で決定できない【満たす】
- 性質 2:現在の状態 $p$ は唯一の状態を表さない [状態 $q$ も表す]【満たす】
- 時間計算量:$O (k\times n)$、非常に大きな定数がある
- マッチングプロセス中に、等価関係を上にジャンプする回数は固定されていない
- 最適化できるか?パス圧縮の考え方に基づいて、以下を参照
最適化#
状態遷移プロセスを一歩で完了させる
- 考察:状態遷移時、等価関係に基づいて上にジャンプするプロセスを一歩で完了できるか?
-

- 現在の状態は $p$、左の図は $p$ の等価関係 [$fail$]
- 前のプロセスでは、右の図の赤い矢印→は $fail$ ポインタを介して中間ジャンプを行う必要がある
- 【目標】赤い矢印を一歩で完了させる
-
- 最適化:無駄を利用する⭐
-

- $p$ の $next$ 配列の中で、$b$ と $c$ は元々空ノードに対応しており、完全に無駄であるため、なぜそれらを等価関係の対応ノードを指すために使用しないのか?同様に、$p'$ もそうである
- ❗ 伝達性に注意:$p$ が $c$ を指す辺は、$p'$ が $c$ を指す辺を通じて伝達できる [レベル順探索、$p'$ が $c$ を指す関係はすでに得られている]、したがって、マッチング関係の最適化プロセスでは、実際には $fail$ 関係に基づいて上にジャンプする必要はない
-
- この時の AC オートマトンは本質的にDFA[決定性有限状態オートマトン] に近い
- 性質 1:現在の状態 $p$ で、入力文字 $c$ の後、1 ステップの操作で次の状態にジャンプできる【満たす】
- 性質 2:現在の状態 $p$ は唯一の状態を表す【満たさない】
- 依然として等価関係が存在するが、ジャンプは一歩で完了できる
- 時間計算量:$O (n)$
ダブルアレイ Trie#
ダブルアレイ辞書木、名の通り、2 つの配列で辞書木を表す
導入#
- 完全二分木
- 思考論理の木構造、実際のストレージ構造は連続した配列空間の一部
- 通常の二分木と比較して:大量の辺のストレージ空間を節約 [左 / 右の子ノードのアドレスを記録]
- 最適化の考え方:記録式 👉 計算式、空間を節約
- n 個のノードの辞書木
- $BASE \times n$ の辺の空間を開放
- しかし、そのうちの $n - 1$ の辺しか使用しない
- したがって、$BASE \times n - (n - 1) = (BASE - 1) \times n + 1$ の辺の空間が無駄になっている
- 👉 完全二分木の利点を参考にして、ダブルアレイ辞書木を提案
- 同様に計算によって子ノードのアドレスを取得し、辺の情報をストレージする必要はない
base 配列#
基準値を保存
- 【親ノードが子ノードを見つけるのを助ける】
- $base [i]$:第 $i$ ノードが保存する $base$ 値
- その第 $j$ 子ノードのインデックスは $base [i] + j$ に等しい
- [PS]$base$ 値は自由に設定でき、負でも繰り返し可能
- 考察:$base$ 配列だけの場合、以下のようなシーンが発生する
-

- ❌ 2 つのノードが同じ番号の子ノードを持つ場合、すなわち 11 番ノードが複数の親ノードに対応する可能性がある [3、5]
- したがって、$base$ 値を設定した後、計算された子ノードのインデックスが既に使用されているインデックスと衝突しないようにする必要がある
check 配列#
親ノードのインデックスを記録
- 【親子鑑定、ノードの親ノードが誰であるかを確認】
- $check [i]$:第 $i$ ノードの親ノードのインデックス
- $base$ 値で計算された子ノードのインデックスにすでに親がいる場合、$base$ 値を変更できる
- ❗ 考察:成詞ノードを記録する方法
- $base$ 値は自由に設定できる
- $check$ 値はインデックスを表し、必ず非負であり、インデックスを 1 から始めることができる [根ノード]
- 👉 $check$ 値の正負を使用して成詞かどうかを示す
- [PS]$check [i]=0$ はインデックス i がまだ使用されていないことを示す
公式化#
- $child_j = base[father] + j$
- $check [child_j] = \left {\begin {aligned}&father & 成詞でない \&-father & 成詞である \&0 & 親がいない \end {aligned}\right.$
- [PS]
- $child_j$:第 $j$ 子ノードのインデックス、$j$ は文字情報に対応する
- $father$:親ノードのインデックス
- $root = 1$、$check[1] = 0$
小結#
- 2 つの配列を使用して辞書木の 2 つの重要な情報を保存
- ① 親子ノード間の木構造関係 [$base$+$check$]
- ② ノードが独立した単語であるか [$check$]
- これにより、大量の辺のストレージ空間を節約する
- 1 つの辞書木👉複数のダブルアレイ、1 つのダブルアレイ👉完全な辞書木
- この時、辞書木も思考論理の木構造に過ぎず、実際には 2 つの連続した配列空間をストレージしている
- ❗ オフラインストレージ構造
- 伝送や復元が非常に便利
- しかし、動的挿入は非常に時間を浪費する
- 実際の使用時には、一度構築し、何度も使用する [クエリ]
+ 二分辞書木#
名の通り、各ノードには 2 つの分岐しかない
- 二進数の文字列を挿入する辞書木で、任意の情報を挿入できる [コンピュータ内の任意の情報は二進数の文字列と見なすことができる]
- 空間を非常に節約するが、時間を浪費する
- 幅を減らし、深さを増やす
- 本質:時間を空間と交換する
- ⭐ 二分辞書木 + ハフマン符号化
- 空間を節約しながら、検索時間を最大限に節約する [深さを減らす]
コードデモ#
Trie#


- 上は辞書木の標準データ構造のコード実装で、問題を解くための技術的実装方法は以下を参照 [HZOJ-282]
- 構造定義
- 26 の文字に対して、ノード内に 26 のノードを対応して保存でき、文字情報を表す 26 の辺と理解できる
- $flag$ を使用して成詞ノードをマークする
- 構造操作
- 単語を挿入しても根ノードのアドレスは変更されないため、関数の戻り値は void である
- 特定のインデックスを指すノードが存在すれば、対応する文字情報が存在することを示す
- ⭐文字列のソート
- $k$ を現在の層数を示すために使用し、$s$ に文字列情報を保存し、末尾に 0 を置くことで、いつでも文字列を出力できるようにする
- 再帰的な方法で深さ優先探索を行い、$k$ を理解することが重要である
AC オートマトン#
通常版#
$next$ 配列が十分に活用されていない




- Trie 木を構築 👉 等価マッチング関係を構築 [キュー、$fail$] 👉 マッチング [状態遷移、単語取得]
- 注意
- 等価関係に基づいて上にジャンプする操作は、マッチングの構築と使用のプロセスだけでなく、単語取得のプロセスでも発生する
- 等価マッチング関係を構築し使用する while ループは、非常に時間がかかり、最適化できる
- [考察:等価関係構築プロセス] 根ノードの子ノードの等価マッチング関係は必ず根ノードを指す

- 64 行目で if を使用する場合、最初のループで $p$ が root である場合を考慮する必要がある
- $c$ は root の子ノードで、$k$ は直接 NULL であり、60 行目で while ループを直接抜けることになるが、62 行目で k が root に設定されると、64 行目で if を使用すると、root->next [i] は必然的に成立する、なぜならそれは root の子ノード自身だからである
- ここでは、根ノードの子ノードを一括で考慮することができるが、最適化版では別途処理する必要がある
最適化版#
$next$ 配列を十分に活用し、構築とマッチングプロセスが最適化された



- 最適化:現在のノードの $next [i]$ が空である場合、直接等価関係の $next [i]$ に設定し [①];そうでなければ、現在のノードの $next [i]$ の等価関係を①に指向させる
- 注意:根ノードは特別な処理が必要で、両方の状況で root 自身に設定する [②]
- [PS]
- 根ノードの $fail$ は NULL を指すのみ
- 解放時には、ノードが辞書木の原生であるかどうかを判断する必要があり、そうでない場合、重複して free するとエラーが発生する可能性がある
- AC 最適化で使用されるノードは原生ノードに対応している
DAT [+AC オートマトン]#






- 【一】まず入力された単語に基づいて Trie を構築する
- 便利さのために、Trie に基づいて DAT を実装する
- $cnt$:辞書木のノード数を記録
- インライン関数を使用し、参考にC 言語におけるキーワード inline の使用法解析——CSDN
- 【二】Trie を DAT に変換する
- 0] そのノードが成詞である場合、$check$ を負に更新
- 1] 子ノードの $check$ を順にマーク
- 2] 子ノードの $base$ を順にマーク
- [PS]
- 最大インデックスを記録
- ノードのインデックスは 1 から始まり、$base$ 値も 1 から始まる
- $base$ 値の決定方法は多くあり、ここでは暴力的な方法を採用
- ⭐ 以下の情報($index\ |\ base\ |\ check$)を使用することで、辞書木情報を変換できる
-

- 変換手順
-

- ① まず根ノード $index=1$ を描き、$|check|=index$ の三元組に対応するインデックスを見つけ、根ノードの子ノードのインデックスを得る
- ② 次に子ノードの子ノードのインデックスを順に見つけ、全体の辞書木の構造を描く
- ③ 最後に、親ノードの $base$ 値と子ノードの番号の差に基づいて、辺に対応する文字情報を得る
- [PS]$check$ 値が負→成詞
-
- 👉 ダブルアレイはファイルに出力するのが非常に便利で、機械間で共有することができ、すなわち DAT を共有する
-
- 上記の辞書木情報に対応する Trie と DAT の実際の空間サイズを比較
-

- DAT の圧縮効率は約 25 倍❗
- 実データセットを利用して、DAT の圧縮効率をテストしてみることができる
-
- [PS] レベル付きのログ情報システムを実装した
- 【三】$fail$ ポインタを追加し、DAT を AC オートマトンに基づく DAT に変換する
- 論理は変わらず、コード実装に注意
- そのノードには第 $i$ 子ノードがある 👉 その子ノード番号に対応する $check$ 値が自分の番号を指す
- パス圧縮を使用する必要はなく、そもそも利用可能な「無駄」がない
- 論理は変わらず、コード実装に注意
授業中の練習#
HZOJ-282:最大異なる対 [Trie]#

サンプル入力
3
1 2 3
サンプル出力
3
- 思考
- 【考察】異なる結果をできるだけ大きくするにはどうするか
- 異なる演算に参加する 2 つの数字は、2 進数表現の各ビットができるだけ異なることが望ましい
- 【問題の変換】
- 1 つの数字を確定する
- 高位から低位までできるだけ異なるもう 1 つの数字を探す [位置が高いほど重みが大きい]
- すなわち最大異なる対を見つける
- 【実装手順】辞書木を使用
- ① 各数字を 2 進数の文字列と見なし、辞書木に挿入する
- ② 貪欲な戦略を採用し、各数字を遍歴して、その対応する異なる値が最大の別の数字を探す
- ③ 最終的に最大の異なる値を得る
- 【考察】異なる結果をできるだけ大きくするにはどうするか
- コード


- ⭐多くのハイライト:すべてのノード空間を直接開放し、順序的にノード空間を使用;ビット演算を巧みに使用;貪欲に遍歴し、クエリしながら挿入
- 構造定義
- 問題の意図に基づき、最大で $31\times 10000$ 個のノードが必要であり、直接開放する
- 符号付き int 型の有効ビットは定長 $31$ ビットであるため、成詞の $flag$ は必要ない
- 構造操作
- 高位から低位まで数字の各ビットを挿入する
- 論理的に正規化して有効ビットを 1 に変換し、$next$ 配列のインデックスとして使用する [0、1 のみ]
- 貪欲な遍歴
- クエリ時に自分自身と異なる演算を行う必要がないため、クエリが完了した後に辞書木に挿入する
- あるビットが 1 を異なることができる場合、ビットまたは演算を使用して答えに加える
伴随プログラミング:文字列統計 [AC]#
【予習】データ構造(C++ 版)

サンプル入力
2
ab
bca
abcabc
サンプル出力
0: 2
1: 1
- 思考
- 多モードマッチング問題 [AC オートマトンの裸題]
- 重要なポイント
- ① 解法のルーチン版コードを実装:大きな配列を直接開放する
- ② 各単語のカウントを維持する:幼稚園で必ず知っておくべきポインタのテクニックを使用
- 注意:入力データに与えられたパターン文字列には重複がある可能性がある
- コード



- [コードの技術を試す]
- 2 つのトリック⭐
- ① 大きな配列を開放し、インデックスでノードを表す
- 配列サイズ [ノード数]:最大 $1000\times 20$
- 空ノードは 0 で表し、次に使用可能なノード番号を記録する
- インデックスを使用する際には、コード実装の思考の変換に注意する
- ② ポインタを利用してパターン文字列と答えを結びつけ、答えの順序を固定し、リアルタイムで更新できる
- パターン文字列の重複の可能性に対して、$ans$ 配列も int * 型を使用し、同じパターン文字列の答えは同じアドレスを指すことができる
- マッチング時には、ポインタのアドレス上の値を操作するだけでよい
- ① 大きな配列を開放し、インデックスでノードを表す
付加知識点#
- 辞書木の本質:辞書データの別の表現形式であり、辞書の本と等価である
- AC オートマトンの本質:状態機械
- 実際のアプリケーションでは、AC オートマトンは辞書木の暴力的マッチングほど広くは使用されない [開発効率と実行効率のバランスにおいて]
- DFA、NFA はコンパイラ原理の知識
- 主な違い:DFA は速度が速く、NFA はメモリを少なく消費する
- 参考Difference between DFA and NFA——Stechies
Tips#
- おすすめ:基本的なアルゴリズムの本や数論の基礎書を何冊か読み、離散数学的思考に多く触れること
- 誤った学習:何が間違っているかを学び、間違いの確率を減らす
- 道を得る者は多くの助けを受け、道を失う者は助けが少ない;万物には成熟した時期がある;小さな歩みを積み重ねなければ千里には至らない;小さな流れを積み重ねなければ江海には至らない
- 寄語:私の矛であなたを武装する