一部の古典的で素晴らしい単一パターンマッチング関連アルゴリズム
コース内容#
関連定義
単一パターンマッチング問題:テキスト文字列 $s$ の中で特定のパターン文字列 $t$ が出現するかを探すこと
複数パターンマッチング問題:複数のパターン文字列 $t$ を探すこと
テキスト文字列 / 母文字列:検索対象の文字列 $s$
パターン文字列:検索する文字列 $t$
テキスト文字列の長さは $m$、パターン文字列の長さは $n$
ブルートフォースマッチング法#
すべての文字列マッチングアルゴリズムの基礎
思想#
- 順番にパターン文字列とテキスト文字列の各位置を整列させ、完全に一致するまで続ける
- その思想はすべてのマッチングアルゴリズムを理解するための基礎:漏れなく答えを見つけること
- 他のアルゴリズムの最適化の核心は重複を避け、成功しない試行を減らすこと
- 時間計算量:$O (m\times n)$
考察#
最初の不一致が発生したとき、ブルートフォースマッチングはどのように処理するのか?
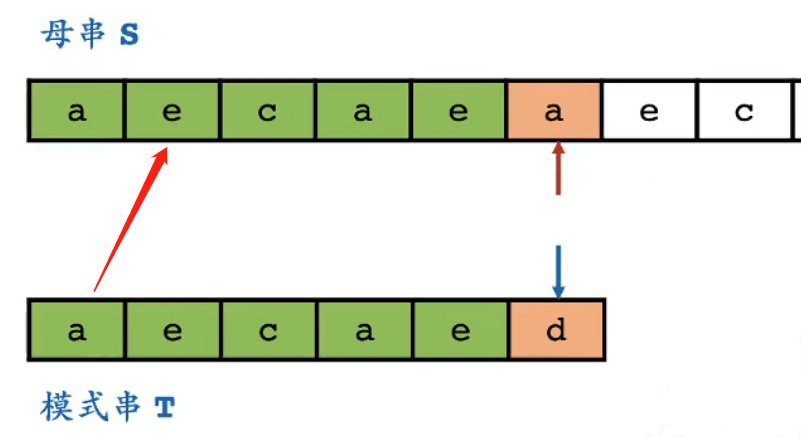
- パターン文字列の最初の位置を母文字列の 2 番目の位置とマッチングさせる
- もしマッチングが成功すれば、パターン文字列の最初の位置とテキスト文字列の 2 番目の位置が等しいことを意味する
- パターン文字列の 2 番目の位置とテキスト文字列の 2 番目の位置がマッチング成功していることがわかっているので
- パターン文字列の 2 番目の位置と最初の位置が等しいことが必然的に存在する
- パターン文字列の 2 番目の位置と最初の位置が等しいかどうかは、パターン文字列を取得した時点でわかる
- 上の図では、パターン文字列の 1 番目の位置を母文字列の 2 番目の位置とマッチングさせる必要は全くない
- それらは確実にマッチしない
- 確実にマッチしない位置をスキップできるかどうか、KMP アルゴリズムには自分の考えがある
KMP#
状態機械の思想、自身の構造の繰り返し展開の概念
思考過程#
続けて、A、B、C の位置に注目
-

- 【仮定】黒い影の部分で不一致が発生した場合、パターン文字列 $t$ は後方に④の大きさだけ移動し、この時テキスト文字列 $s$ の②とパターン文字列 $t$ の①がマッチング成功する場合
- 【重要】第③部分:その左境界が $t$ の後方移動の距離を決定する [同第①部分の右境界]
- 【A】この縦列では、必ず②=③=①が存在し、②は不一致位置に隣接している 👉 ③も不一致位置に隣接している
- 【B】③は実際には $t$ の接尾辞で、①は $t$ の接頭辞 👉 ③は $t$ のある接頭辞に等しい
- 【C】漏れなくマッチングを保証するために、④はできるだけ小さくするべき 👉 ③はできるだけ大きくするべき
- 【結論】以上のことから、③を通じてマッチングプロセスを加速でき、③は不一致位置に隣接した、$t$の最長接頭辞である
問題の変換#
不一致時に対応する③の大きさを事前に得ることは、また①の大きさでもある
-

- パターン文字列の①と③を探し、①の後ろの緑の文字を使って②の後ろの不一致位置のオレンジの文字とマッチングする
- パターン文字列の各位置を考慮する必要がある:不一致の位置はパターン文字列の各位置である可能性がある
- パターン文字列は事前に知られている;テキスト文字列は知られておらず、制御できない
- 👉 パターン文字列の $next$ 配列
next 配列#
- $next [i]$:$i$ の位置がマッチング成功したが、$i+1$ の位置が不一致になったときに使用し、次回のパターン文字列のマッチングのオフセットとして
- 状態定義:$i$ の位置で終わる接尾辞の中で、マッチング可能な最長接頭辞のインデックス [右境界]
-

- パターン文字列にのみ適用
-
- 移行公式:図を見て理解し、図中の①②に注目
- $next[i+1]=\left{\begin{aligned}&next[i]+1&t[i+1]=t[next[i]+1]\&next[next[i]]+1&t[i+1]\neq t[next[i]+1]\ &&\ t[i+1]=t[next[next[i]]+1]\&next[next[next[...[i]]]]+1&until\ equal\ or\ the\ end\end{aligned}\right.$
-

- まず第二、三行を見て、①を判断する
- もし $t [i+1]=t [next [i]+1]$ であれば、$i+1$ に対応する最長接頭辞は $next [i]+1$ である
- そうでなければ、$t$ をできるだけ短い距離だけ右に移動させる [上記の思考過程の④に類似]、つまり部分文字列 $t [0\to j]$ の中で、$j$ で終わる接尾辞に対応する最大接頭辞を見つける [これが $next$ 配列の定義]
- 第一、二行を観察し、②を判断する
- もし $t [i+1]=t [next [j]+1]$ であれば、$i+1$ に対応する最長接頭辞は $next [j]+1$ であり、ここで $j=next [i]$
- そうでなければ、$t$ を右に移動し続け、③④... 等しい関係が満たされるまで判断する、または $t$ がこれ以上右に移動できない
- 動的計画法の思想が含まれており、《面接筆記アルゴリズム下》にジャンプできます ——1 再帰から動的計画法へ(上)
- 理解を深める練習
- 仮想位置を定義:-1 [いかなる接頭辞にもマッチしない場合、値は - 1]
- 練習 1
-

- 練習 2
-

- 答え:
-1、-1、0、-1、0、1、2、3、4、5、6、1
- [PS] 参考KMP アルゴリズムの詳細——CSDN
- 文中の $next$ 配列は、接頭辞と接尾辞の最大共通長さとして定義されている [文字列そのものを含まない、さもなければ最大長は常に文字列そのものである]
- $next$ 配列の定義は一意ではないことがわかる
- 自身の構造の繰り返し展開の概念、$next$ 配列を求める際にこの思想がある
マッチングプロセス#
- テキスト文字列 $s$ の各位置を順番に走査する
- パターン文字列 $t$ の開始位置からマッチングを開始する
- もしテキスト文字列 $s$ の現在の位置がパターン文字列 $t$ の現在の位置と等しい場合、次の位置のパターン文字列 $t$ をマッチングする
- そうでなければ、$next$ 配列に基づいてパターン文字列 $t$ の試行マッチング位置をどんどん前に移動させ、等しい条件が成立するまで、パターン文字列 $t$ の次の位置をマッチングする;またはこれ以上前に移動できない場合、テキスト文字列 $s$ の次の位置をマッチングする
- パターン文字列 $t$ の末尾に成功裏にマッチングできた場合、テキスト文字列 $s$ に対応するマッチング位置を出力する;または見つからなかった
小結#
- パターン文字列の第③部分の重要性を理解する [思考過程を参照]
- マッチング速度を加速する核心であり、大量の無駄なマッチング試行を避ける
- 漏れを保証する核心:第③部分がマッチングしたのはパターン文字列の最長接頭辞である
- 状態機械の観点から理解でき、コードデモを参照 —— 状態機械版 KMP
- 時間計算量:$O (m + n)$
- [PS] KMP にはいくつかの最適化方法も存在する
SUNDAY#
尻を探してから頭を探す
シミュレーション操作#
以下の状況を直接シミュレートする
- ① 不一致が発生したとき、パターン文字列 $t$ の末尾に対応する母文字列 $s$ の次の位置e を観察する ——黄金の整列ポイント
-

- [注意] 不一致位置の次の位置を観察する < 図に誤解されないように >
-
- ② パターン文字列 $t$ の中で、後ろから前に最初のe の位置を探す
-

- 倒数第 2 位で e を見つける
-
- ③ 倒数第 2 位は、パターン文字列 $t$ が母文字列 $s$ に対して正確に 2 位右に移動し、再び母文字列 $s$ とのマッチングを試みることを意味する
-

- [個人的理解] この右移動が成功するためには、e の位置が整列する必要がある、なぜなら必ず e を通過するから;最初の e を探すのは、答えを漏らさないためである
-
- ④ 上の図でも不一致が発生した場合、再びパターン文字列 $t$ の中で後ろから最初の a を探し、整列し、マッチング... 成功するまで、またはマッチングが終了するまで
- [PS] 黄金の整列ポイントに対応する文字が見つからない場合、右移動のオフセットはパターン文字列 $t$ の長さ + 1 となる
プロセス#
- パターン文字列の各文字が最後に出現した位置を事前に処理する
- ブルートフォースマッチングアルゴリズムのプロセスをシミュレートし、不一致のとき、テキスト文字列のポインタは上記の事前処理情報に基づいて、対応する位置に後ろに移動し、再びマッチングする
- 最終的に、マッチングが成功した場合はインデックスを返す、または見つからない
小結#
- 核心:黄金の整列ポイントを理解する [シミュレーション操作を参照]
- マッチングが成功した場合、必ずパターン文字列の中に存在する
- それはパターン文字列の中でその文字が最後に出現した位置と整列するべきである
- 右移動操作:探している文字がパターン文字列の倒数第何位に出現するかによって、テキスト文字列のポインタを右に移動させる
- 最速の時間計算量:$O (m /n)$
- 対応するシナリオ:探している黄金の整列ポイントの文字がパターン文字列の中に見つからない場合、テキスト文字列のポインタはパターン文字列の長さ $n + 1$ の距離だけ後ろに移動する
- [PS]
- 最悪の時間計算量:$O (m\times n)$、しかしこのような場合に対応する文字列は一般的に実際的な意味を持たない
- 使用シナリオ:単一の単語を文章の中で探すなどの単純な単一パターンマッチング問題 <工業で非常に一般的>
- KMP と比較すると
- SUNDAY は理解しやすく、実装も簡単
- しかし KMP アルゴリズムの思考方式はより高度で、学ぶべきである [状態機械]
SHIFT-AND#
非常に美しいニッチアルゴリズム、想像力を試す
状態機械の思想:NFA、非決定性有限状態オートマトン
コード配列 d#
⭐パターン文字列をある種のコードに変換し、変換後はマッチング問題がパターン文字列とは全く関係なくなる
-

- 0 番目の位置から始めて、パターン文字列 t の各位置を順番に読み取る
- 0 番目の位置で 'a' 文字が出現した場合、$d$ 配列のインデックス 'a' の要素を 0 番目に 1 を設定する
- 1 番目の位置で 'e' 文字が出現した場合、$d$ 配列のインデックス 'e' の要素を 1 番目に 1 を設定する
- このようにして $d$ 配列を得る
- [PS]
- $d$ 配列のインデックスは文字の ASCII コードに対応できる
- $d$ 配列の要素は int 型 [32 ビット]、long long 型またはカスタム型を格納でき、これがマッチング可能な最長パターン文字列の長さを決定する
- 文字列の順序と $d$ 配列要素の数字の順序に注意、0 番目の文字は後者の低位に対応する
状態情報 p#
状態定義を理解し、状態を移行する感覚を持つ
- 状態定義:$p_i$
- $p_i$ の二進数表現の中で、もし第 $j$ 位が 1 であれば、テキスト文字列 $s [i]$ で終わるとき、パターン文字列の前 $j$ 位を成功裏にマッチングできることを示す
- 図解、上記の定義と以下の三対の円を対照させる
-

- 赤色:$p_4$ はテキスト文字列 $s [4]$で終わる、現在のマッチング条件を示す
- オレンジ色:$p_4$ の第 2 位が 1 であれば、パターン文字列 $t$ の前 2 位が上記のマッチング条件を満たすことを示す、すなわち $t [0\to 1]$ が $s [3\to 4]$ とマッチングする
- 緑色:$p_4$ の第 5 位が 1 であれば、パターン文字列 $t$ の前 5 位が上記のマッチング条件を満たすことを示す、すなわち $t [0\to 4]$ が $s [0\to 4]$ とマッチングする
- [PS]
- $p$ の二進数の長さは、どのデータ型を使用するかによって決まる、$d$ 配列要素と同様、int の場合は 32 ビット
- $p_4$ がどのように得られるかは、後で移行プロセスを見て確認する
-
- ⭐このように見える
- $p$ は同時に複数のマッチング結果の情報を保持している❗
- $p_i$ の第 $n$ 位が 1 であれば、マッチング成功であり、すなわち
- $p_i\ &\ (1\ <<\ (n-1))=1$
- マッチング位置は:$i-n+1$
- 移行プロセス:$p_i=(p_{i-1}\ <<\ 1\ |\ 1)\ &\ d [s [i]]$
- ⭐重要な公式⭐
- この時点でパターン文字列 $t$ を完全に無視し、$p$ の前の状態と $d$ 配列を通じて、現在の $p$ の値を得ることができる
- 原理分析、重要な公式と下図の①②を対照させる
-

- $p_3$ が既知であると仮定し、現在 $s [2\to 3]$ と $s [0\to 3]$ をマッチングできる
- ①左に 1 ビットシフト+または 1 演算を行い、遷移状態 $p_4^{'}$ を得る
- 左に 1 ビットシフト:前のマッチングの基礎の上に $s [4]$ を飲み込むことを試み、すなわち $s [2\to 4]$ と $s [0\to 4]$ をマッチングする
- マッチング成功の条件は後の【論理積演算】に依存する
- [注意] 左シフト操作は図中では右シフトとして表現される、なぜなら数字の順序は低位が前に来るから
- または 1 演算:$s [4]$ を単独でマッチングする機会を残す、マッチング成功はこの 1 文字をマッチングすることを示す
- 左に 1 ビットシフト:前のマッチングの基礎の上に $s [4]$ を飲み込むことを試み、すなわち $s [2\to 4]$ と $s [0\to 4]$ をマッチングする
- ②論理積演算
- 上記の 2 つの操作はすべてマッチングを試みるだけであり、実際の成功は $d [s_4]$ の結果に依存する
- もし第 $j$ 位の論理積演算の結果が 1 であれば、$s [4-j+1\to 4]$ が $t [0\to j-1]$ とマッチングすることを示す
- 例えば $p_4 [2]=1$、$p_4 [5]=1$、マッチング結果は状態定義部分の図解に相当する
-
- [PS]
- $p$ の初期値は 0 であり、$p$ は実際には非決定性有限状態オートマトンである
- 習慣的な衝突:一般的に数字の順序の右側は低位であるが、図中の $p$ の左側は低位である;二進数の数字の最低位は 1 であり、文字列の最低位は 0 である;$d$ 配列要素は数字であるため、数字の順序に対応するべきであるが、上図はパターン文字列との対応位置関係を示すために文字列の順序を使用している
- $p$ の意味を正確に理解する:前回成功裏に 4 位をマッチングした場合、次回は 5 位を成功裏にマッチングする可能性がある
- 64 ビットを超える文字列マッチング問題については、自分でデータ型を作成する必要がある
- 左シフト、または、または、論理積演算をサポートする必要がある
- その後、コード配列 $d$ と状態情報 $p$ の型を対応して修正する
小結#
- ① コード配列 $d$:パターン文字列中の各文字が出現した位置を、対応する二進数コードに変換する
- ② 状態情報 $p$:重要な公式 $p_i=(p_{i-1}\ <<\ 1\ |\ 1)\ &\ d [s [i]]$ を通じて状態を移行する
- 時間計算量:$O (m)$
- パターン文字列を往復する必要は全くない
- しかし厳密に言えば、純粋な $O (m)$ ではなく、これはコンピュータのデータ表現能力に関係している
- ❗ 正規表現マッチング問題を解決できる
- 例えば:$(a|b|c)&(c|d)&e&(f|a|b)$
- ① 上記のパターン文字列をコード配列 $d$ に変換する
- $d$ 配列の各列には複数のビットを持たせ、1 に設定する
- すなわち、パターン文字列の各位置は複数の【$d$ 配列の要素】の対応する二進数ビットを 1 に設定できる
- ② その後はパターン文字列とは無関係になり、$d$ 配列と重要な公式に基づいて問題を解決する
- [PS] ここでパターン文字列がパターン文字列と呼ばれる理由は、文字列だけでなく、正規表現も指すからである(関連性のある複数のパターンと見なすこともできる)
コードデモ#
ブルートフォースマッチング法#

- 2 つのバージョン、簡潔なバージョンのテクニックを学び、$flag$ を柔軟に使用する
- テキスト文字列とパターン文字列をそれぞれ走査し、逐次的に等しいかを判定し、不一致の場合はテキスト文字列のポインタを 1 つ右に移動させる
- この思想はすべての文字列マッチングアルゴリズムの基礎である
KMP#
2 種類のプログラミング方式、後者はアルゴリズムの本質的な思想により近い
- ① 通常のコーディング:$next$ 配列を直接取得し、次に $next$ 配列を使用して不一致オフセットを行う

- $next$ 配列を事前処理→テキスト文字列の各位置を走査→パターン文字列をマッチング [$next$ 配列を利用]
- ❗ 観察:$next$ 配列を取得するプロセスとテキスト文字列をマッチングするプロセスは非常に似ており、状態機械の思想に基づいて、2 つの部分を統合できる
- ② 高度なプログラミング:状態機械の思想に基づき、$next$ 値を取得するプロセスを状態の変化プロセスに変換する

- 状態機械モデルを抽象化した:$j$ が指し示すのは状態機械の位置であり、$getNext$ メソッドは入力文字に基づいて状態をジャンプさせる、実際には $j$ の値を変更することに相当する
- KMP の本質により近い思考方式
- PS:マッチング成功して $i-n+1$ を返す前に $next$ 配列を free するべきである
SUNDAY#

- ❗ 256 の意味に注意:各文字がパターン文字列の中での位置を記録するために使用される
- $offset$ 配列の事前処理プロセス:最初にすべて出現しない状態で初期化し、$n+1$ はテキスト文字列のポインタが直接パターン文字列の長さ + 1 の距離だけ右に移動できることを示す;事前処理の過程で、後の同じ文字の出現位置が前の位置を上書きし、SUNDAY の意図に合致する
- $s [i + n]$:黄金の整列ポイントに対応する文字
- $i + n <= m$:$n$、$m$ 変数を合理的に利用し、テキスト文字列がまだパターン文字列とマッチングするのに十分であることを示す
- KMP と比較すると、SUNDAY は理解しやすく、コードの実装も簡単である [単純な単一パターンマッチング問題を解決するための最良の選択]
SHIFT-AND#

- ⭐ 思想が美しく、コードが簡単
- 注意
- 数字に関連する $d$ 配列要素と状態 $p$ の最低位は 1 である;一方、文字列は 0 に対応する
- しかし移行プロセスは数字間の演算であるため、位置が整列しているかどうかを気にする必要はない
随堂練習#
——Hash——#
よく使われる解法のパターン
HZOJ-275:ウサギとウサギ#

サンプル入力
aabbaabb
3
1 3 5 7
1 3 6 8
1 2 1 2
サンプル出力
Yes
No
Yes
- 思考
- 注意:クエリの回数が非常に多く、クエリ範囲が非常に大きいため、ブルートフォースマッチングは必ずタイムアウトする
- どのように迅速に比較するか?👉 ハッシュマッチングアルゴリズム
- ハッシュ操作を通じて文字列を数字 <ハッシュ値> で表現する
- もし 2 つの文字列に対応するハッシュ値が異なれば、2 つの文字列は必ず等しくない
- こうして大部分の不等しい場合を排除でき、ビットごとに比較する必要がなくなる
- そうでなければ、ブルートフォースマッチングで文字列が等しいかを確認する
- もし 2 つの文字列が等しければ、一度のマッチングで成功する
- [PS]
- 長い文字列に直接対応するハッシュ値は非常に大きくなる可能性があるため、一般的には剰余操作でハッシュ値を縮小する
- 剰余が異なれば 👉 文字列は確実に異なる
- ハッシュ関数を設計する [文字列 -> ハッシュ値]
- $H=(\sum_{k=0}^{n-1}{C_k\times base^k})%P$
- $n$:文字列 $s$ の長さ
- $C_k$:第 $k$ 位の文字に対応する ASCII コード値
- $base$:位重み [素数]
- $P$:法 [素数]
- [PS] 文字はコンピュータの底層で二進数の数字として保存されている
- ⭐本題における部分文字列 $s [j\to i]$ のハッシュ値 $H_{j\to i}$
- 文字列とハッシュ値の関係に基づいて、ハッシュに基づく前方和配列を事前に処理することができる
- $HS_i=(\sum_{k=0}^{i}{C_k\times base^k})%P$
- したがって、部分文字列 $s [j\to i]$ のハッシュ値は
- $HS_{j\to i}=(\sum_{k=j}^{i}{C_k\times base^k})%P$
- しかし部分文字列のハッシュ値は、文字列中の部分文字列の位置情報 $j$、$i$ を含むべきではなく、すなわち乗数因子は $base^0$ から始めるべきである
- したがって、区間和 $HS_{j\to i}$ を $base^j$ で割る必要があるが、剰余演算では直接割り算を行うことはできず、逆元を利用する必要がある
- 最終的な部分文字列 $s [j\to i]$ のハッシュ値 $H_{j\to i}$ は次のように変換される
- $H_{j\to i}=HS_{j\to i}\times(base^j)^{-1}%P=(HS_i-HS_{j-1})\times(base^j)^{-1}%P$
- $(base^j)^{-1}$:$base^j$ の逆元
- 逆元の迅速な求解については、迅速に [モジュール] 逆元を求めることにジャンプしてください
- 文字列とハッシュ値の関係に基づいて、ハッシュに基づく前方和配列を事前に処理することができる
- 解法①
-
- テキスト文字列上で、各位置に基づくハッシュの前方和を事前に処理し、後で区間和を求めるのを便利にする
-
- 区間和と逆元を通じて、部分文字列 $s [i\to j]$ のハッシュ値を求める:
- $H_{j\to i}=HS_{j\to i}\times(base^j)^{-1}%P$
-
- 2 つの部分文字列のハッシュ値を比較する
- もし異なれば、部分文字列は必ず異なる
- そうでなければ、ブルートフォースマッチングで等しいかを確認する
- ❗ 2 つの部分文字列が異なっていても、そのハッシュ値が等しい可能性は $1/P$ である
-
- 解法②
- 解法①に基づき、2 つのハッシュ関数を設計し、$P$、$base$ を異なるものにする
- 2 つの部分文字列に対応する 2 つのハッシュ値を比較する
- 両方が等しい場合、2 つの部分文字列は同じと見なす
- そうでなければ、必ず異なる
- ❗ 2 つの部分文字列が異なっていても、そのハッシュ値が等しい可能性は $1/(P_1\times P_2)$ である
- エラーの確率は非常に低く、実際には多くのアルゴリズムが確率的アルゴリズムである
- コード
- 解法①:ハッシュマッチング + ブルートフォースマッチング


- ①$P$ 値は素数でなければならず、さもなければ一部の逆元は意味を持たず、対応するハッシュ値が正しくない
- これにより、同じ部分文字列が異なるハッシュ値に対応する可能性がある
- 逆元が存在するための十分条件は、互いに素であること
- ② long long 型を使用する必要があり、中間プロセスの数値は非常に大きくなる可能性がある
- これにより、異なる部分文字列が同じハッシュ値に対応する確率が増加し、時間がかかる [ブルートフォースマッチング]
- [PS]
- 常に剰余を考慮し、数値が表現範囲を超えないようにし、long long であっても
- ハッシュ値が正であることを保証することに注意
- ハッシュに基づく前方和配列 $H$ は単調増加ではない、なぜなら和を求める際に剰余演算が行われるからである
- $P$ 値が小さすぎると、タイムアウトの原因となり、ブルートフォースマッチングの回数が多くなる
- 解法②:ハッシュマッチング * 2


- 注意:2 つの逆元配列を別々に初期化し、完全に初期化されることを保証する [走査範囲が異なる]
- または同じ $P$ と異なる $base$ を使用して、一緒に初期化することができる
- [PS] 安全のため、ブルートフォースマッチングの検証を追加することができる
迅速に [モジュール] 逆元を求める#
⭐推導過程
- 目標:$x\times x^{-1}\equiv1\ (mod\ P)$ の中で $x^{-1}$ を求める
- [PS] $x<P$ のケースのみ考慮する、なぜなら $P$ より大きいすべての $x$ は剰余を取ることで $P$ より小さい $x$ に変換できるからである
- 令:$P\ %\ x=r,P\ /\ x=k$
- したがって:
- $\begin{aligned}P&=kx+r\kx+r&\equiv0\ (mod\ P)\kx(x^{-1}r^{-1})+r(x^{-1}r^{-1})&\equiv0\ (mod\ P)\kr^{-1}+x^{-1}&\equiv0\ (mod\ P)\x^{-1}&\equiv-kr^{-1}\ (mod\ P)\\end{aligned}$
- 最終的に $x^{-1}$ を求める問題を $r^{-1}$ を求める問題に変換する
- ここで $r$ は $x$ の剰余であるため、$r$ は必ず $x$ より小さい
- 大規模な問題 👉 小規模な問題 [再帰]
- 逆元が正であることを保証するために、もう一度処理を行う
- $x^{-1}_{+}=(-kr^{-1}\ %\ P+P)\ %\ P$
- [PS]
- モジュール逆元:逆元が存在するための十分条件は $p$ と $x$ が互いに素であること
- 逆元を求める方法は多く、参考に逆元の知識普及 (啓蒙編)——cnblogs
コード
-

- モジュールが何であれ、1 の逆元は 1 である [初期化]
- 出力結果
-

- 自分で検証可能:元の数と逆元を掛け合わせて剰余を取ると 1 になる
-
追加の知識点#
- KMP、SHIFT-AND の本質的な思想:状態機械 <コンパイラ原理で学ぶ知識>
- SUNDAY アルゴリズムは日常生活で非常に一般的であり、ハッシュマッチングアルゴリズムは問題解決でよく使用される
- DFA、NFA はコンパイラ原理の知識
- 主な違い:DFA は速度が速く、NFA はメモリを少なく消費する
- 参考にDifference between DFA and NFA——Stechies
ヒント#
- C++ の前に、必ず予備課程を終えておくこと
- アルゴリズム分野の専門家になるためには、自分の美的感覚を高めることが重要である
- 怒ることは無能の表れであり、正しいことをする!一歩一歩良くなり、一気に成功を求めないこと